本文系作者编译,授权“正义补丁”独家首发。转载需征求许可,规范署名(公号名/ID/作者),违者必究
作者:Moreless
字数:8066
预计阅读时间:20 分钟
封面图来自于原文截图
编者按:这是《科学美国人》2020年12月的一篇分析社交媒体上假新闻传播特点的文章。上个月写《喜欢传谣的“有用的傻瓜”们到底都是谁?》的时候引用了这篇文章中的一个结论。文章的题目是:Information Overload Helps Fake News Spread, and Social Media Knows It,这是一篇非常有趣的文章,原文作者分别是印第安纳大学信息和计算机系教授Filippo Menczer,和英国华威大学教授Thomas Hills。文章虽然比较偏学术,但是读起来很顺畅,对普通读者来说,阅读也没有什么门槛。以下是它的全文翻译。
现在来说一说安迪,他担心会感染新冠。由于无法阅读他所看到的所有相关文章,他只能依靠信得过的朋友的提示。
当一些人在Facebook上认为疫情流行的恐惧被夸大了时,安迪起初并不相信这种说法。但是后来他工作的酒店关门了,由于他的工作处于危险之中,安迪开始怀疑这种新病毒的威胁到底有多严重。毕竟,他认识的人中没有人死于新冠。一位同事发布了一篇文章,说对Covid-19的恐慌是大药厂与腐败的政客互相勾结造成的,这与安迪对政府的不信任相吻合。他的网络搜索很快将他带到了声称Covid-19并不比流感更糟糕的文章中。安迪加入了一个由已经被解雇或者担心被解雇的人组成的在线小组,并很快发现自己像他们中的许多人一样问:“哪门子疫情?”当他得知他的几个朋友正计划参加一个要求结束封锁的集会时,他决定加入他们。在这次大规模的抗议活动中,几乎没有人戴口罩。包括他在内。当他的姐姐问起集会 的情况时,安迪分享了现在已经成为他身体一部分的信念:Covid就是一场骗局。
这个例子很好的说明了认知偏见这样一个雷区,我们更喜欢来自我们信任的人,即我们圈内人的信息。我们关注并愿意分享有关风险方面的信息。对安迪来说,就是失去工作的风险。我们搜索并记住了那些与我们所了解和能理解的东西相吻合的事情。这类偏见是我们过去进化的产物,数万年来,这种观念为我们服务得很好,所谓“小心驶得万年船”。按照这些偏见行事的人 — 例如,远离有人说有毒蛇的杂草丛生的池塘岸边 — 比那些不这样做的人更有可能生存。
然而,现代技术正在以有害的方式放大这些偏见。搜索引擎将安迪引向那些激发他怀疑的网站,而社交媒体将他与志同道合的人联系在了一起。更糟糕的是,机器人(即冒充人类的社交媒体账户,又被称作僵尸账号),使误导或者恶意行为者能够利用人的弱点。
使问题更加复杂的是网上信息量的激增。查看和制作博客、视频、推特和其他被称为 “段子”的信息单元已经变得如此便宜和容易,以至于信息市场(information marketplace)被淹没了。由于无法处理所有这些材料,我们的认知偏见决定我们应该注意什么。这样心理方面的捷径影响了我们搜索、理解、记忆和重复哪些信息的方式,其达到了有害的程度。
了解这些认知上的弱点,以及算法如何使用或操纵这些弱点的需求已经变得非常迫切。在英国华威大学(University of Warwick)和印第安纳大学布鲁明顿分校( Indiana University Bloomington)的社交媒体观察站(OSoMe,发音为 “awesome”),研究团队正在使用认知实验、模拟、数据挖掘和人工智能来理解社交媒体用户的认知漏洞。
在华威大学进行的关于信息演变的心理学研究,为印第安纳大学开发的计算机模型提供了信息,反之亦然。他们还在开发分析和机器学习辅助工具,以打击社交媒体操纵行为。其中一些工具已经被记者、民间社会组织和个人用来检测不真实的行为者,绘制虚假叙事的传播图,并培养新闻素养。
信息过载(Information Overload)
信息过剩产生了对人们注意力的激烈争夺。正如诺贝尔经济学奖得主、心理学家赫伯特·A·西蒙(Herbert A. Simon)所指出的,“信息消耗的结果是相当明显的:它消耗了接受者的注意力。” 所谓注意力经济的首要后果之一是高质量信息的流失。
OSoMe团队通过一组简单的模拟来演示这一结果。它将安迪等社交媒体用户称之为用户代理(agent),作为在线熟识人网络中的节点。在模拟的每个时间步骤中,代理可以创建一个段子,或者转发他或她在新闻提要中看到的内容。为了模仿有限的注意力,代理只被允许查看其新闻时间线顶部附近的一定数量的项目。
OSoMe的Lilian Weng在许多时间步骤中运行这一模拟,发现随着代理的注意力越来越有限,段子的传播反映了实际社交媒体的指数律分布:一个段子被分享一定次数的概率大致是该数字次方的反比。例如,一个帖子被分享三次的可能性大约是其被分享一次的九倍。

代表3个社交媒体网络的节点图显示,更多的网络段子与更高的信息过载和更低的信息共享质量相关。资料来源:”有限的个人注意力和低质量信息的在线病毒式传播”,作者Xiaoyan Qiu等,载于《自然-人类行为》,第1卷,2017年6月。
社交媒体的时间线充斥着各种内容,而像我们一般用户只能看头几条,从中选择分享和转发。OSoMe的研究者模拟了这种有限的注意力。模型网络中的每个节点代表一个用户,接收信息并分享的朋友或者follower/粉丝/关注者,被用线连接起来。研究者发现,随着网络转发的次数越多,广泛传播的内容的质量就会越下降。所以信息过载本身就可以解释为什么假新闻可以病毒式传播。
网络段子这种赢家通吃的模式,即大多数的内容没有人注意到,而少数内容得以广泛传播。不能用其中一些更吸引人或者某种程度上更有价值来解释。这个虚拟世界中的网络段子并没有内在质量。病毒式传播,纯粹是由注意力有限的用户组成的社交网络中,信息扩散的统计结果造成的。OSoMe的研究人员Xiaoyan Qiu发现,即使代理优先分享高质量的内容,所观察到的那些分享最多的内容,整体质量并没有改善。模型显示,即使我们想看到和分享高质量的内容,我们也无法看到新闻线中的所有内容,这不可避免地导致我们分享部分或者完全不实的内容。
认知偏差大大加剧了这个问题。在1932年的一组开创性研究中,心理学家弗雷德里克·巴特利特(Frederic Bartlett)向志愿者讲述了一个美国原住民的故事:一个年轻人听到了战争的呼喊,为了追随这些呼喊,他进入了一场如梦如幻的战斗,最终导致了他的死亡。巴特利特要求非原住民的志愿者在几分钟到几年后,以越来越长的时间间隔回忆这个相当混乱的故事。他发现,随着时间的推移,回忆者倾向于扭曲故事中文化上不熟悉的部分,以至于它们要么从记忆中消失,要么被转化为更熟悉的事物。我们现在知道,我们的大脑一直在这样做:他们调整我们对新信息的理解,使其与我们已经知道的东西相一致。这种认知偏见的一个后果是,人们经常寻找、回忆和理解那些最能证实他们已经相信的信息。
这种倾向是非常难以纠正的。实验一再表明,即使人们遇到了包含不同观点的平衡信息,他们也倾向于为自己已经相信的东西找到支持性证据。而且,当对气候变化等带着情绪化的问题有着不同信仰的人,看到关于这些话题的相同信息时,他们甚至会更加坚持自己的原有立场。
更糟糕的是,搜索引擎和社交媒体平台根据其掌握的关于用户过去偏好的大数据提供个性化的推荐。他们在我们的信息源中优先考虑我们最可能同意的信息 — 无论是多么边缘化 — 并阻止我们接触可能改变我们想法的信息。这使得我们很容易成为观点两极化的目标。东北大学的Nir Grinberg和他的同事们最近的研究表明,美国的保守派更容易接受错误信息。
但我们自己对推特上低质量信息消费的分析表明,这种脆弱性适用于政治光谱的双方,没有人可以完全避免它。甚至我们检测在线操纵的能力也受到我们政治偏见的影响,尽管不是对称的。共和党用户更有可能将宣传保守思想的机器人误认为是人类,而民主党人则更有可能将保守的人类用户误认为是机器人。
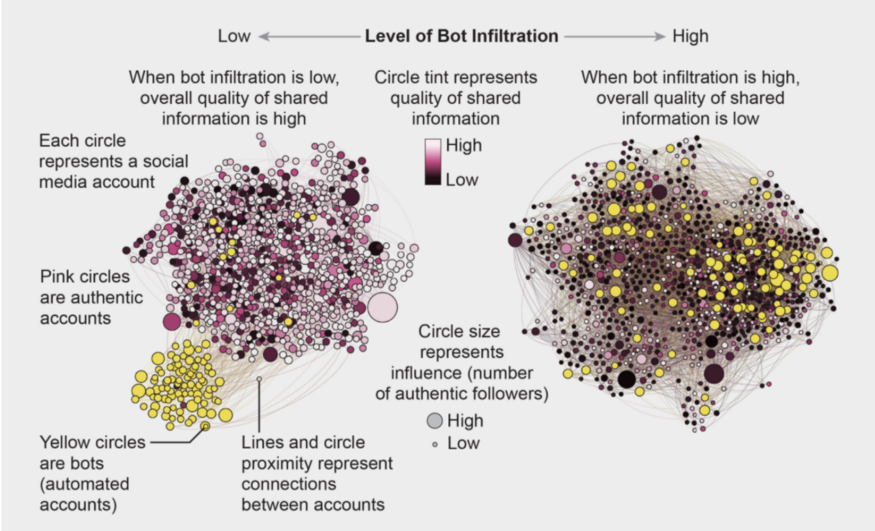
代表2个社交媒体网络的节点图显示,当超过1%的真实用户关注机器人时,低质量的信息会占上风
机器人,或者叫做僵尸账号,它们模仿真实用户,极大地降低了社交网络上信息的质量。在一个计算机模拟中,OSoMe的研究者把机器人(这种代理模型只发没有质量的推,并且只转发一次)加到社交网络里来。他们发现,当关注机器人的真人用户比例小于百分之一时,信息质量还是高的,左图。当关注机器人的比例高于1%时,低劣信息就传遍了整个网络。机器人在传播开始阶段的少量几个点赞就可以使假信息病毒式传播。
社会羊群行为(Social Herding)
2019年8月在纽约市,人们开始从听起来像枪声的地方跑开。其他人紧随其后,有些人喊着:“枪手!” 后来人们才知道,这些爆炸声来自一辆倒车的摩托车。在这种情况下,先跑后问可能会有好处。在没有明确信号的情况下,我们的大脑利用关于人群的信息来推断适当的行动,类似于鱼群和鸟群的行为。
这种社会从众心理是存在的。在2006年一项涉及1.4万名网络志愿者的研究中,当时在哥伦比亚大学的马修·萨尔加尼克和他的同事发现,当人们可以看到别人在下载什么音乐时,他们最终也会下载类似的歌曲。此外,当人们被隔离到各个社交群体中时,他们可以看到自己圈子里其他人的偏好,但是没有圈外人的信息,个体的选择会迅速发生了分化。但“非社交性”群体的偏好,即没有人知道其他人的选择,则保持相对稳定。换句话说,社交群体创造了一种强大的一致性压力,以至于它可以压过个人偏好,并通过放大随机的早期差异,可以导致这种与外部隔离的群体分化到极致。
社交媒体也遵循类似的动态。人们通常将受欢迎程度与信息质量混为一谈,并最终自食其果。Bjarke Mønsted和他在丹麦技术大学和南加州大学的同事在Twitter上的实验表明,信息是通过 “复合传染(complex contagion)”传播的:当我们反复接触到一个想法,通常是来自许多来源,我们更有可能采用并转发它。这种社会偏见被心理学家所称的 “单纯接触(mere exposure)”效应进一步放大:当人们反复接触相同的刺激物,如某些面孔,他们会逐渐喜欢这些刺激物,而不是那些他们不常遇到的刺激物。
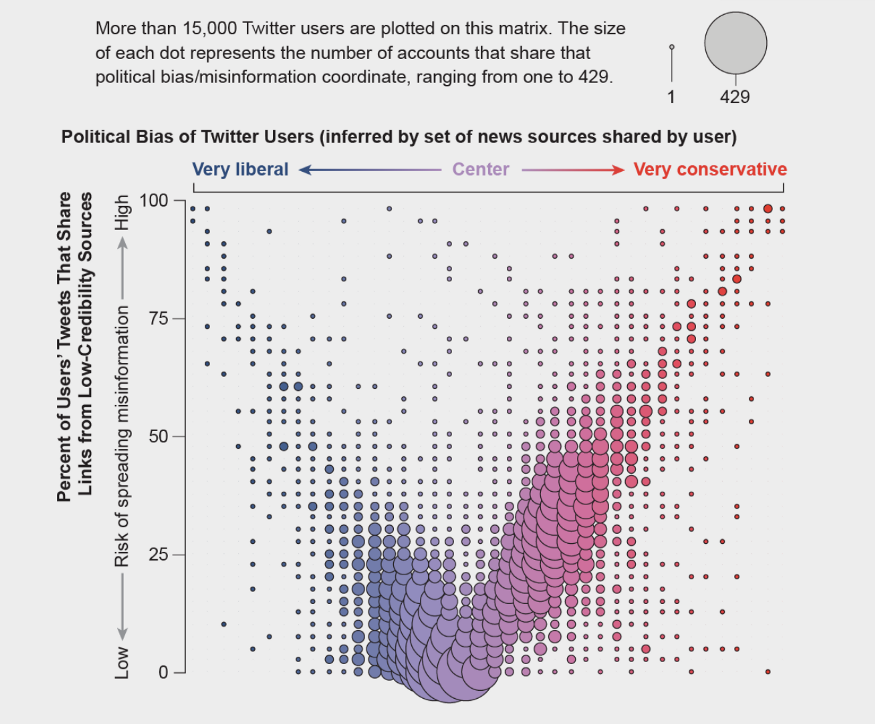
具有极端政治观点的推特用户比温和的用户更有可能分享低可信度来源的信息
资料来源。迪米塔-尼科洛夫和菲利普-门采尔(数据)。
一项对推特用户标注他们的政治倾向的研究发现,保守主义者(上图中红色的点)和自由派(上图中蓝色的点)都会分享反复发布假新闻的(被独立信息核查员标记为)低可信度网站的内容。但是,保守主义者某种程度上更易于分享假新闻。
这种偏见转化为一种不可抗拒的冲动,即关注那些正在病毒式传播的信息 — 如果其他人都在谈论它,那么它一定很重要。除了向我们展示符合我们观点的项目外,Facebook、Twitter、YouTube和Instagram等社交媒体平台还将热门内容放在我们屏幕的顶部,并向我们展示有多少人喜欢和分享了某件事。我们当中很少有人意识到,这些提示并不能提供对信息质量的独立评估。
事实上,设计社交媒体上的内容排名算法的程序员认为,“群众的智慧”会迅速识别高质量的内容;他们用受欢迎程度来代表质量。对大量关于匿名点击的数据分析表明,所有的平台 — 社交媒体、搜索引擎和新闻网站 — 都倾向于提供来自流行来源的一小部分的信息。
为了了解原因,我们模拟了社交媒体如何在排名中结合质量和受欢迎程度。在这个模型中,注意力有限的代理 — 那些只在新闻时间线的顶部看一定数量的项目的人 — 也更有可能点击平台排名较高的帖子。每个项目都有内在的质量,以及由它被点击的次数决定的受欢迎程度。另一个变量跟踪排名在多大程度上依赖于受欢迎程度而不是质量。这个模型的模拟显示,即使在没有人类偏见的情况下,这种算法的偏差通常也会抑制帖子的质量。即使我们想分享最好的信息,算法最终还是会误导我们。
回音室(Echo Chambers)
我们中的大多数人都不相信我们会跟着羊群走。但是,我们的认知偏见使我们追随那些与我们相似的人,这种动态有时被称为 “同癖” (homophily)— 志同道合的人相互联系的倾向。社交媒体通过允许用户通过关注、取消好友等方式改变他们的社交网络结构,放大了同质性。其结果是,人们被隔离在大型的、密集的和日益错误的社区中,通常被描述为回音室。在OSoMe,我们通过另一个模拟,EchoDemo,探索了在线回音室的出现。在这个模型中,每个人都有一个政治观点,用一个数字表示,范围从-1(例如,自由派)到+1(保守派)。这些倾向性反映在人的帖子中。人也会受到他们在新闻线中看到的意见的影响,他们可以取消对意见不同的用户的关注。从随机的初始网络和意见开始,我们发现,社会影响和取消关注的结合大大加快了两极化和隔离社区的形成。
事实上,Twitter上的政治回音室是如此极端,以至于个人用户的政治倾向可以被高度准确地预测出来:你和你的大多数连接者拥有相同的观点。这种腔室结构有效地在一个社区内传播信息,同时将该社区与其他社群隔绝开来。2014年,我们的研究小组被一场虚假信息活动所针对,声称我们是出于政治动机压制言论自由的一部分。这种错误的指控主要在保守派的回音室中病毒式传播,而事实核查人员的揭发文章则主要在自由派社区中被发现。可悲的是,这种将假新闻与它们的事实核查报告隔离开来的做法是常态。
社交媒体也可以增加我们的负面情绪。在最近的一项实验室研究中,同样在华威大学的罗伯特·贾吉尔洛(Robert Jagiello)发现,社会共享的信息不仅支持我们的偏见,而且对其纠正也变得更加困难。他调查了信息如何在所谓的社会扩散链中从一个人传到另一个人。在实验中,链条上的第一个人阅读了一组关于核电或食品添加剂的文章。这些文章被设计成平衡的,包含了尽可能多的正面信息(例如,关于更少的碳污染或更持久的食物)和负面信息(例如熔毁的风险或可能对健康的伤害)。
社交传播链中的第一个人告诉下一个人这些文章,第二个人告诉第三个人,以此类推。我们观察到,随着负面信息沿着链条的传递,负面信息的数量总体上有所增加,这被称为风险的社会放大。此外,澳大利亚新南威尔士大学的丹妮尔·J·纳瓦罗(Danielle J. Navarro)和她的同事的工作发现,社会扩散链中的信息最容易被具有最极端偏见的个人所扭曲。
更糟糕的是,社会扩散还使负面信息更加 “固执”。当贾吉尔洛随后让社交传播链中的人接触到原始的、平衡的信息 — 也就是链中第一个人看到的新闻 — 平衡的信息对减少个人的负面态度没有什么作用。经过人们传递的信息不仅变得更加消极,而且更加抗拒更新。
OSoMe研究人员费拉拉(Emilio Ferrara)和Zeyao Yang在2015年的一项研究中分析了关于Twitter上这种 “情绪传染 “的经验数据,发现过度接触负面内容的人倾向于随后分享负面帖子,而过度接触正面内容的人则倾向于分享更多正面帖子。因为负面内容比正面内容传播得更快,所以通过创建引发恐惧和焦虑等负面反应的叙事,可以很容易用来操纵情绪。现任南加州大学的费拉拉和他在意大利布鲁诺·凯斯勒基金会的同事表明,在西班牙2017年关于加泰罗尼亚独立的公投中,社交机器人被利用来转发暴力和煽动性的叙事,增加了他们的曝光率,加剧了社会冲突。
机器人的崛起(Rise of the Bots)
信息质量因社交网站机器人而进一步受损,机器人可以利用我们所有的认知漏洞。机器人很容易创建。社交媒体平台提供了所谓的应用程序接口(API),使得建立和控制成千上万的机器人变得相当简单。要放大一个信息的影响,即使只是在Reddit等社交媒体平台上的机器人早期的几次点赞,也会对一个帖子的后续流行产生巨大影响。
在OSoMe,我们已经开发了机器学习算法来检测社交机器人。其中,Botometer是一个公共工具,它从一个给定的Twitter账户中提取了1200个特征,以描述其个人情况、朋友、社会网络结构、时间活动模式、语言和其他特征。该程序将这些特征与数万个先前确定的机器人的特征进行比较,给该Twitter账户是否是机器人账号打分。
2017年,我们估计多达15%的活跃Twitter账户是机器人 — 它们在2016年美国大选期间虚假信息传播中发挥了关键作用。在一篇假新闻发布后的几秒钟内 — 比如一篇声称克林顿竞选团队参与了神秘仪式的文章 — 就会被许多机器人推送到推特上,而人们被表面上受欢迎的内容所欺骗,会转发它。
机器人还通过假装代表我们群体中的人来影响我们。一个机器人只需要关注、喜欢和转发一个网络社区中的某个人,就能迅速渗透到这个社区。OSoMe研究员Xiaodan Lou开发了另一个模型,其中一些代理是渗透到社交网络中的机器人,并分享具有欺骗性的吸引人的低质量内容来骗取点击率。该模型中的一个参数描述了一个真实的人将关注机器人的概率 — 这就是这个模型的目的,我们将其定义为产生零质量的帖子并只相互转发的代理。我们的模拟表明,这些机器人只需渗透到网络的一小部分,就能有效地抑制整个生态系统的信息质量。机器人还可以通过推荐关注其他不真实的账户来加速形成回音室,这种技术被称为创造 “关注列车”(follow trains)。
一些操纵者通过独立的假新闻网站和机器人来扮演分歧的两方,推动政治两极化或通过其发广告赚钱。在OSoMe,我们最近在Twitter上发现了一个由同一实体协调的虚假账户网络。一些人假装是 “让美国再次伟大 “运动的亲川普支持者,而另一些人则冒充是川普的 “抵抗者”。所有这些人都要求政治捐款。这种行动放大了利用认知偏差的内容,并加速了两极化回音室的形成。
遏制网上操纵行为(Curbing Online Manipulation)
了解我们的认知偏差以及算法和机器人是如何利用这些偏见的,可以让我们更好地防范被操纵的行为。OSoMe已经制作了一些工具,帮助人们了解自己的弱点,以及社交媒体平台的弱点。
其中一个是一个名为Fakey的移动应用程序,帮助用户学习如何发现虚假信息。该游戏模拟社交媒体的新闻源,显示来自从低信誉到高信誉来源的实际文章。用户必须决定他们可以或不应该分享什么,以及如何进行事实核查。对Fakey的数据分析证实了网上社交群体的普遍性:当用户相信有很多其他人分享了同一文章时,他们就更有可能分享这些低可信度的文章。
另一个向公众开放的程序,名为Hoaxy,显示了任何现存的帖子是如何通过Twitter传播的。在这个可视化程序中,节点代表实际的推特账户,而链接则描述了转发、引用、提及(被@)和回复是如何在账户之间传播该帖子的。每个节点都有一个颜色,代表它在Botometer中的得分,这让用户可以看到机器人放大错误信息的规模。这些工具已被调查记者用来揭示错误信息活动的根源,例如在美国推动 “披萨门(pizzagate)”阴谋的活动。然而,随着机器学习算法在模仿人类行为方面变得更好,操纵行为也越来越难以被察觉。
除了传播假新闻,虚假信息造势运动还可以转移对其他更严重问题的注意力。为了打击这种操纵行为,我们最近开发了一个名为BotSlayer(机器人杀手)的软件工具。它可以提取用户希望研究的话题的推文中共同出现的标签、链接、账户和其他特征。对于每个实体,BotSlayer跟踪推文、发布推文的账户和它们的机器人分数,以标记正在流行的实体和可能被机器人或协调账户放大的实体。其目的是使记者、民间社会组织和政治候选人能够实时发现和追踪不真实的影响力活动。
这些程序工具是重要的辅助工具,但要遏制假新闻的泛滥,还需要进行制度上的变革。教育可以有所帮助,尽管它不可能涵盖人们被误导的所有话题。一些政府和社交媒体平台也在努力打击网上操纵和假新闻。但谁来决定什么是假的或操纵性的,什么不是呢?信息可以带有警告标签,例如Facebook和Twitter已经开始提供的警告标签,但应用这些标签的人是否值得信任?这些措施可能会有意或无意地压制言论自由,而言论自由对健全的民主制度至关重要,这种风险是真实的。具有全球影响力并与政府关系密切的社交媒体平台的占有的主导地位,使这种可能变得更加复杂。
最好的办法之一,可能是使创造和分享低质量的信息变得更加困难。这可能涉及到增加难度,迫使人们付费分享或接收信息。付费的形式可以是时间、脑力劳动,如拼图,或订阅使用小额费用。自动发布应该像发放广告一样对待。一些平台已经在使用验证码(CAPTCHA)和电话确认等方式来确认用户的访问。Twitter已经对自动发帖进行了限制。这些努力可以逐步扩大,将在线分享的激励机制转向对消费者有价值的信息。
结论
自由交流是不免费的(Free communication is not free),是有代价的。通过降低信息的成本,也降低了它的价值,并招致假信息的泛滥。为了恢复我们信息生态系统的健康,我们必须了解不堪重负的大脑的脆弱性,以及如何利用信息经济来保护我们不被误导。









